



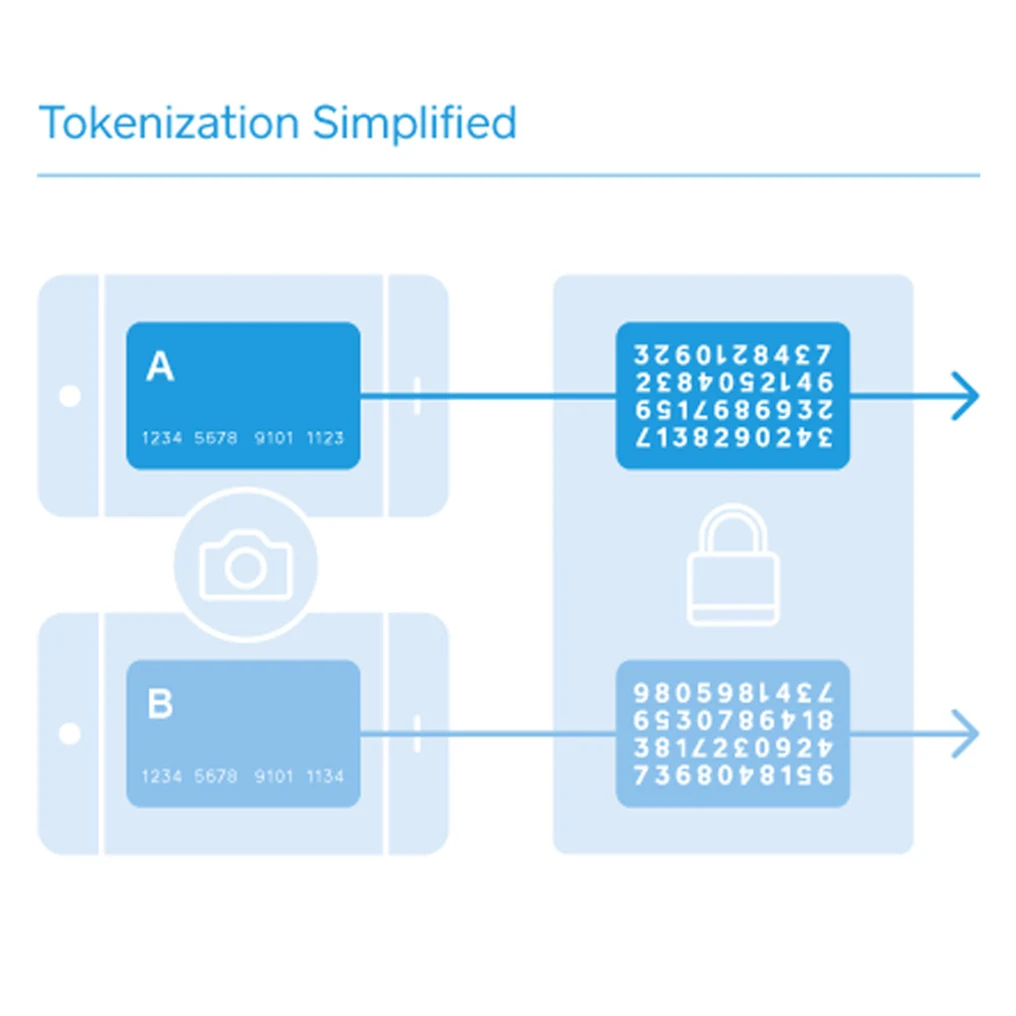

It means a process of replacing original sensitive data elements with different values that are called tokens. It is a form of encryption, but in fact, specialists use those terms differently. Usually, encrypting is made by encoding data into obscure text that is only available for decoding with a special key. Unlike this, tokenization is made by converting data into non-damaging replacement values of the same length and format. Those replacing values are called tokens.
Repeatedly generating a token of the same value generates the same token. So, tokenization is deterministic.
Each element of the data bank is provided with a unique token.
Tokenization is the best solution for protecting data privacy for any kind of business.
Make sure Your Sensitive Data is Safe with Tokenization
Tokenization can play a vital role in a data security service solution, thus becoming an increasingly popular way to protect data. Nowadays, data security service is a must-have for any business dealing with transactions. There are many such services that provide a variety of tokenization methods to fit any need.
What is the origin of this technology?
The first case of using tokenization happened in 2001 when it was invented by TrustCommerce to help clients secure sensitive payment information of their customers. Clients used to store delicate data on their servers. That made data vulnerable to unpredictable hacker attacks.
TrustCommerce came up with the idea of replacing original account numbers with a randomized number that is called a token. This allowed using altered data instead of real account numbers when accepting payments. Since businessmen no longer had real sensitive data on their servers, this isolated risks to TrustCommerce.
First-generation proved the value of this solution. However, the safety concerns and regulatory requirements grew, and imperfections of tokenization became understandable. We will discuss them below.
What are the available types of tokenization?
There are two types of tokenization: reversible and irreversible.
Reversible tokens can be reversed back to their original values, meaning they are detokenized. This is called pseudonymization. This type of token can be also divided into cryptographic and non-cryptographic, although this is unnecessary. In fact, any tokenization is a form of encryption.
The main feature of cryptographic tokenization is generating tokens using strong cryptography. Only the cryptographic key is stored. Examples of such tokenization are NIST-standard FF1-mode AES.
Originally, non-cryptographic tokenization was made by creating tokens by randomly generating a value and storing the cleartext and corresponding token in a database. This approach may appear simple, but in fact, this means complexity and risk, and not scaling well. Let’s consider a request to tokenize a value. The server must first look up a database to see if it already has a token for that value. If so, the server returns it. In another case, it generates a new random value and then performs another database lookup to ensure that value has not been assigned to another piece of data before. If it already exists, the server generates another value and so on. Slowly but steadily the amount of time required for creating a new token increases. There are methods to ensure the reliability of such databases, but they add further complexity.
Modern tokenization focuses on “stateless” or “faultless” approaches and mostly is not cryptographic. It uses randomly generated metadata securely combined to build tokens. Even if disconnected from each other, such systems still can operate, unlike database-backed tokenization.
If tokens are irreversible, it means that they cannot be converted back to their original values. This is called anonymization. This allows the use of anonymized data elements for third-party analytics, production data in lower environments, etc.
Benefits of tokenization
It can be implemented with minimal changes. It also adds strong data protection to existing applications. Unlike traditional encryption solutions, tokenization does not enlarge the data. It means that no changes to the database and program data schema or additional storage are required. Tokens also use the same data formats and can pass validation checks.
Tokenization is much easier to add than encryption because applications share data, and with using tokenization data exchange processes are unchanged. Typically, intermediate data uses don’t even have to detokenize a token to use it. This adds extra protection to original data.
Tokens can partially retain original values, for example, the leading and trailing digits of a credit card number. This allows using a token to perform required functions – such as card routing and verification or printing on customer receipts without converting the token to the original value.
Direct use of tokens improves performance and security. Performance – by requiring no overhead, and security, because the cleartext is never recovered.
What is tokenization mostly used for?
It is mainly used to secure sensitive data, such as:
· names, addresses, birthdates
· passport numbers
· driver’s license numbers
· telephone numbers
· email addresses
· bank account numbers
· payment card data
· etc.
Merchants, companies, and businesses find tokenization appealing because the data-stealing cases rise, and keeping data safe becomes increasingly vital, while tokenization is an easy way of securing data than traditional encryption and is not difficult to integrate.
PCI DSS Compliance
One of the most common use cases for tokenization is securing transaction data. Partly because of the “last four” verification of card numbers and routing requirements for different card types. It also got promoted by demands arranged by the Payment Card Industry Security Standards Council. PCI DSS requires transaction card data to be secured using strict cybersecurity provisions. Businesses also need to use tokenization to meet conformity standards. Tokenization is much painless to add than encryption because transaction data flows are high performance, well-defined, and complex.





{kind=link}